Optiver’s approach to network devices and Infrastructure as Code

About the author

Carlo is a software engineer with a background in offensive cybersecurity and hardware. They joined Optiver’s Platform team in 2022 to develop our bespoke network abstraction layer.
Table of Contents
Some weeks ago, my colleague Nicolás Demarchi wrote a post about Infrastructure as Code (IaC) at Optiver. Building on Nico’s post, I’d like to take the opportunity to go into more depth on the implementation of some of the subsystems, with a focus on networks.
In this post, I’ll lay out some of the challenges, framed in the context of IaC, and how we solved them. Many of our solutions are bespoke implementations of popular concepts, an advantageous approach that allows us great flexibility of implementation.
We’ll cover two areas: device data audits, also known as our secret grey field IaC recipe, and device provisioning.
Implementing IaC in grey field environments
One of the first topics Nico highlighted is the need for a standard. This is undoubtedly true, especially for new data centres or colocations, but one of the goals is implementing IaC in a grey field environment. In other words, the solution should be able to tolerate some degree of manually executed changes, so that operations can continue while these systems are being built.
This is a priority, because as a trading company, we don’t get to pull out of the markets for extended periods of time while infrastructure is being rebuilt to new, more manageable and automatable standards. Solving this problem involves a concept Nico introduced in his post: automated audits.
When we start managing parts of our infrastructure via code, we need to ensure that the state doesn’t diverge over time. One way to do this would be to periodically redeploy all devices, but that can create other problems. For example, network switches may fail during configuration reloads. This failure can have severe implications, especially when it involves trading-critical applications.
Our solution: data collection and intent system comparison
Our solution involves periodically collecting data from devices and comparing it to the intended state in our intent system.
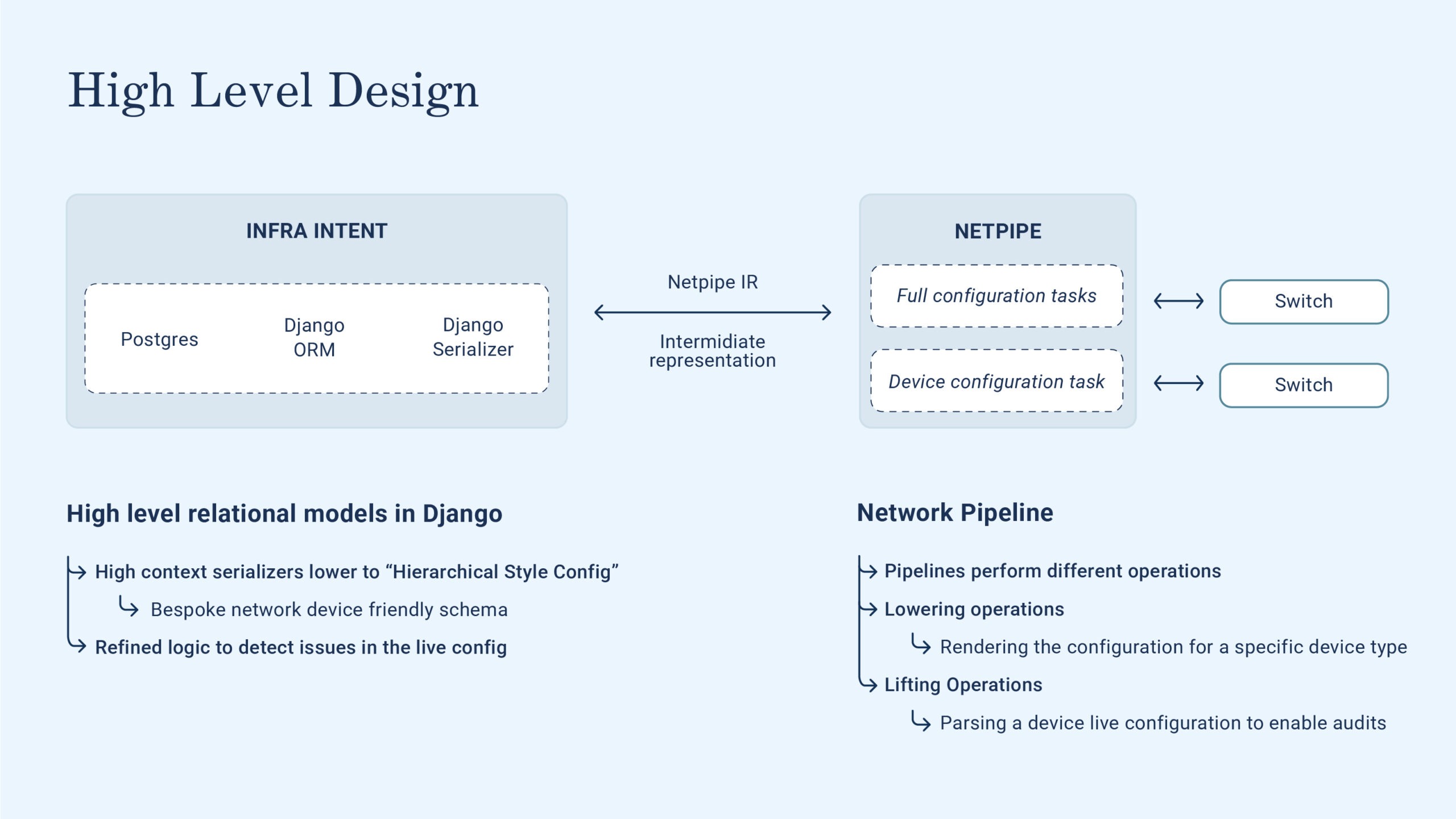
Figure 1: High Level
This requires the following components:
- An intent system: At Optiver we call this “Infra intent”, and it’s implemented as a Django application. The idea here is that Infra intent is the sole entity that holds our desired state, or as we say at Optiver, the intended configuration. Given its role of oracle, this system is also responsible for ensuring that the data doesn’t diverge over time.
- A hardware abstraction layer for the network devices: At Optiver we call this Network Pipeline, which is a Python application that can interact with a lot of devices from different vendors via a bespoke abstraction layer built on top of NAPALM and some custom pipelines.
The network configuration audit flow relies heavily on these two systems. Let’s dig deeper into how the interaction between these systems works.
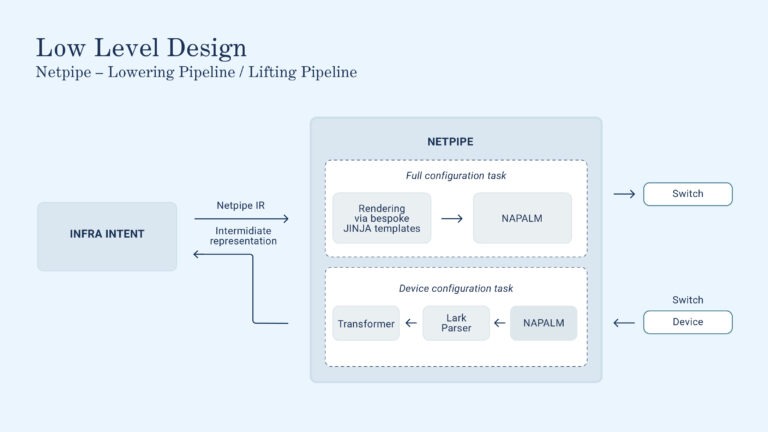
Figure 2: Low level
Focusing on Network Pipeline, you can see that workflows are composed of a series of pipelines, of which we will describe two below device config audits and configuration deployment. Network Pipeline supports tasks, defined as a series of pipelines, but currently we don’t rely heavily on this feature.
Network configuration audits
Defining infra intent
As mentioned in Nico’s blog, everything starts with ‘intent’, because it’s the keeper of the “default state” for our devices. The Django models in intent provide a comprehensive view over our entire infrastructure, making it the perfect system to implement complex business logic. This logic is crucial to check if the state of devices has diverged from what it was intended.
Daily, Infra Intent dispatches a series of tasks to Network Pipeline, the so-called “device truth pipeline”. These pipelines represent one of the core hardware abstraction layer functionalities of Network Pipeline. In short, they provide a unified state representation of the configuration of all network devices in our compute fabric.
Our primary goal is to write only one refined business logic component within our Infra Intent. This logic, referred to as ‘audits’, is crucial as it ensures correctness of our network configurations, while maintaining the flexibility to use the best type of device for each function in our network.
Optiver’s tech stack is so optimized that we can’t afford to make decisions like, “We only buy devices from vendor X, so we only develop integration with those devices.”
Enhancing vendor flexibility with open-source solutions
To achieve this level of flexibility, we integrate two powerful open-source projects. The first is NAPALM, a set of Python libraries that wraps many of the vendor-provided SDKs into one coherent library. We rely heavily on NAPALM, as it’s a convenient way to abstract many of the common interactive tasks without relying on legacy technologies like Expect.
While it’s a great start, NAPALM doesn’t entirely meet our requirements, especially in terms of multi-vendor support and handling complex interaction patterns. For example, NAPALM can parse the configuration of the device interfaces, but it struggles with parsing the BGP configuration. This feature is only partially supported for Arista devices, and we need to support other vendors as well. We spent some time thinking about a holistic way to solve this issue and we came up with a Look Ahead Left to Right (LALR) parser, based on Lark.
Lark parsers for network device configuration
Lark is a Python library that implements a LALR parser in pure Python. It has some limitations, for example, only supporting one-token lookaheads, but it’s definitely a great tool to help build a coherent overview of your infrastructure. Before moving on, let’s dive into how parsers work, and this will serve as the context to justify the seemingly more complex implementation.
LALR parsers fundamentally split the tasks of interpreting the data at hand in two steps. The first one is deriving an abstract syntax tree, based on a grammar. This abstract syntax tree provides an abstract syntax representation of each element of the configuration. This is great, because with a good grammar we can encode all states of the switch configuration inside the tree, without having to rely on things like complex regexes.
This tree is still fairly tied to the configuration of the device, with many elements still vendor-dependent, but now we can build a transformer to shape the AST data into a standardised data structure that we can then use in Infra intent. Transformers are amazing, and with Lark they are even better. Effectively they are just a series of operations that you perform on the AST tree, starting from the leaf and ascending in the graph. Each base token is converted to the final representation, and more complex tokens are built by combining together already converted children.
This is particularly handy when parsing BGP peers, or route maps. All the configuration complexity is dealt with in the grammar, and the transformer is flexible enough to be able to lift all of these configurations into a standardised data structure.
We have found this approach amazing for two reasons:
- It’s very much rooted in great computer-science principles. Parsers and AST are quite well known in the literature, providing a vast resource of knowledge on how to test and maintain them.
- It’s extremely easy to extend for new features. This is great, because alternatives based on regexes tend to increase exponentially in complexity, especially if supporting complex configurations.
This set of open-source projects allows us to effectively gain a coherent view of the state of all of our network devices. The encoding is no longer device-specific, but rather completely agnostic. We call this approach “lifting the device configuration”.
Borrowing from many other applications such as LLVM or QEMU, we also have an intermediate language that we use to represent the configuration of a device. This enables us to have the same exact representation for all devices, and unsurprisingly, it comes in extremely handy when provisioning the devices.
Lowering the configuration, aka provisioning a device
So far we have introduced many concepts, a key one being representing the status of the device in an intermediate form. As we have seen, this allows us to lift the configuration to a higher abstraction level via a mixture of NAPALM and Lark, but this wouldn’t be done if we couldn’t do the opposite as well.
Conceptually this part is much easier, since it’s based on a set of commonly used technologies. We need an extra set of assurances, mainly around how we allow engineers to interact with the provisioning pipelines and how we validate deploys.
One of the main sets of controls we have is the idea of a device state. For the provisioning pipelines to run, the device must be in a maintenance state, and this state can be changed only via an explicit command by an engineer. If the device is in maintenance mode, the provisioning pipeline can be run.
To aid the engineer in validating the changes, we have built a Monaco-based diff visualisation framework, that will show the differences between the running config and the candidate config in a familiar VS Code-like environment.
After the engineer has validated the changes, they can proceed with triggering a deployment to the production devices. This will dispatch netpipe pipeline that will fetch the current intended device state from Infra intent and use a series of bespoke Jinja templates to lower it to the appropriate device configuration.
We then use NAPALM to push this configuration to the device, completing the task of deploying a new device.
A career in Infrastructure Software Engineering
I hope this post provided some helpful insights into the implementation challenges we’ve encountered in the context of IaC, how we’ve chosen to solve them within our network, and why we’re enthusiastic about those solutions.
If these sound like the kind of challenges you’re looking for in your own career, take a look at our job posts below or reach out to [email protected].





