From ideation to production: US tech intern summer projects

Foreword by US CTO, Alex Itkin
One of the most exciting parts of summer at Optiver is hosting the ever growing intern cohort. This summer in the US alone we had 35 interns working across our software, hardware and trading infrastructure teams. The goal of the internship is to give students an opportunity to spend a summer working closely side by side with Optiver’s engineers and traders on solving real problems and pushing code into production.
For the last couple of years, the interns have come up with a way to produce stats on what they were able to accomplish in their 10 weeks. It’s quite impressive how quickly everyone gets ramped up and how much gets done in a summer! We’ve included some of those stats below and write-ups about a few of the projects that interns worked on in 2023.
Aggregate stats:
- Total Repos Touched: 99
- Total LOC Touched: 577,345
- Total Commits: 4,046
- Total JIRA Tickets Picked Up: 130
- Total Production Events Resolved: 32+
- Total Pull Requests Created: 435
- Total Pull Requests Successfully Merged: 364
- Total Releases to production: 93
2023 Tech intern projects
- Data factory integrated storage tier management
- Expanding research factory access
- Generalized framework for generating back populated datasets

Data factory integrated storage tier management
Berke Lunstad, Vanderbilt University
Challenge
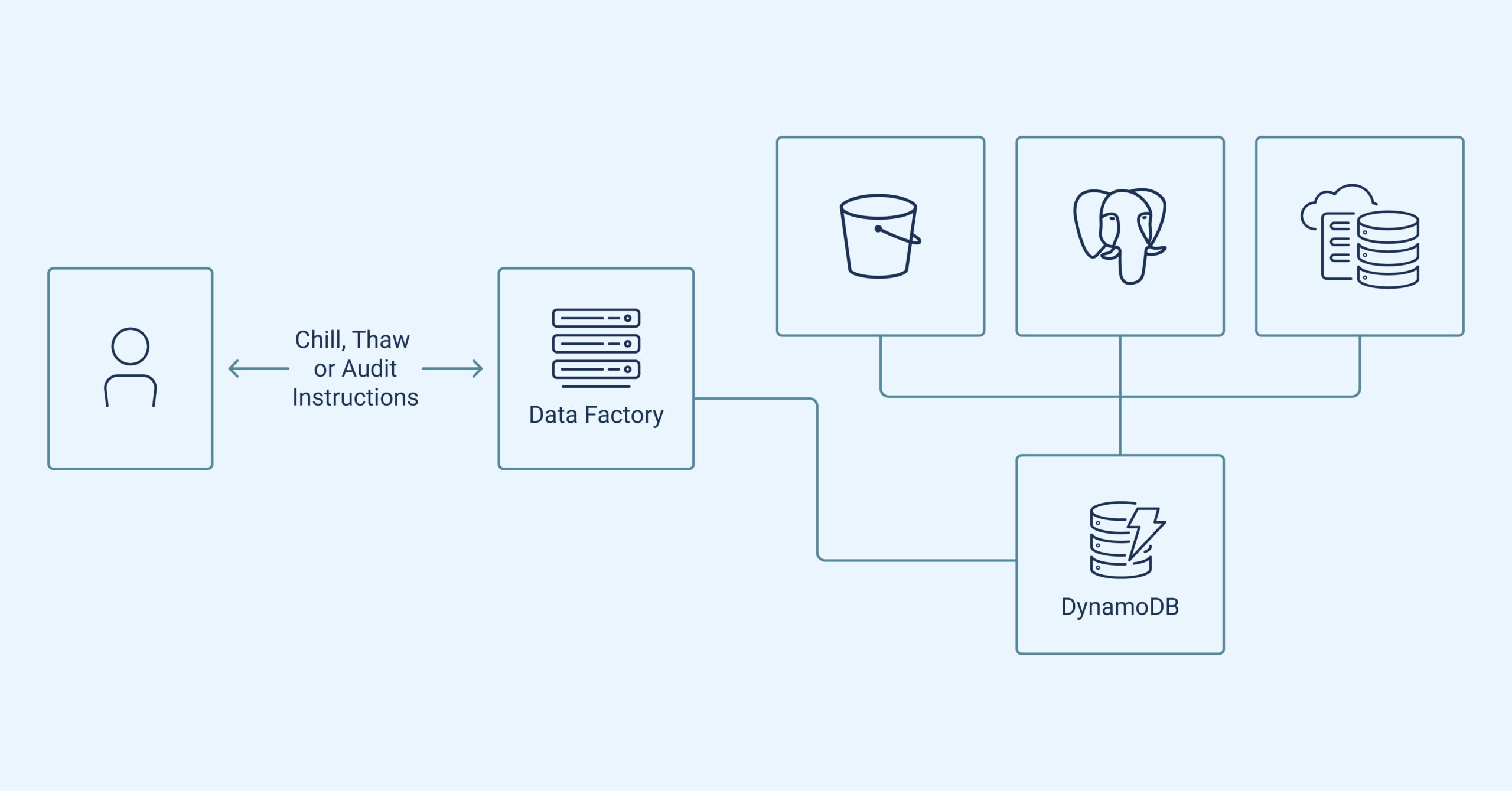
In the trading domain, data is at the center of many challenges. Efficient datasets are vital for insightful market decisions. At Optiver, we handle vast amounts of real-time data, accumulating terabytes daily from global trades, alongside petabytes of historical data for analysis, research and testing. Our in-house data management system, Data Factory, aims to simplify routine data operations allowing researchers, traders and developers to harness data for trading solutions. Storing petabytes in high-performance mediums is expensive, so we transition infrequently accessed data to more affordable, albeit slower, storage like AWS S3 Glacier Deep Archive—costing a fraction of regular S3.
Retrieving large amounts of data from cold storage can often take days, unlike instant access. Pre-internship, this type of data transfer was complex and varied across teams, hindering object status checks and retrievals via Data Factory APIs.
Approach
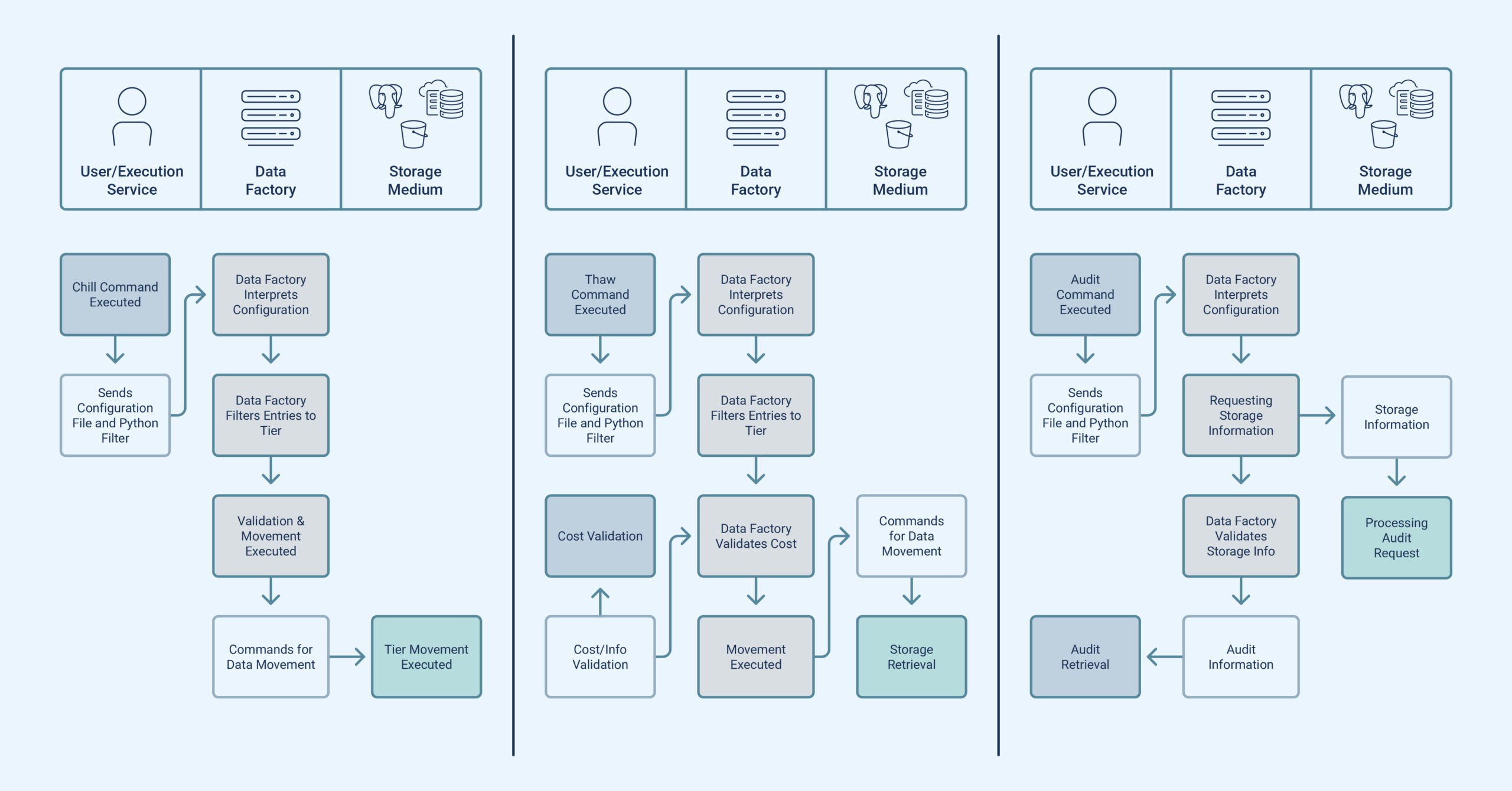
My project involved expanding Data Factory to address these issues. Given the diverse data challenges, a universal solution for moving data to and from cold storage wasn’t feasible. Instead, Data Factory required adaptable handling of various data lifecycle scenarios. My solution involved utilizing NoSQL databases like AWS’ DynamoDB and Data Factory to reference data in S3, NFS, SQL, and other storage locations.
Improving Data Factory’s capabilities required me to add metadata to objects within Data Factory for storage and retrieval information. I also developed three tools: Chill, for configuring datasets and moving data to cold storage using Python-based filters; Thaw, for secure retrieval with similar settings; and an audit tool that enhances safety and alerts users about unexpected data movements or tracking lapses.
Results
My solution efficiently centralized tracking of petabytes of data across different storage tiers and mediums, simplified how data is moved into cold storage and extended existing Data Factory APIs to allow for easy retrieval. These changes now allow teams to spend more time extracting value from their data and less time thinking about how to manage their data costs. By making it easier for users to move data in and out of cold storage, teams also save thousands of dollars per month by easily moving less utilized data to cheaper storage tiers.

Expanding research factory access
Krishna Reddy, The University of Texas at Austin
Challenge
Optiver’s researchers undertake complex financial market analyses, employing an in-house efficiency-enhancing framework named Research Factory. This framework ensures research work remains reproducible, adaptable and easily debugged. While it provides job introspection after completion, a key drawback is its inability to offer real-time insights or recover lost information in case of abnormal job failure.
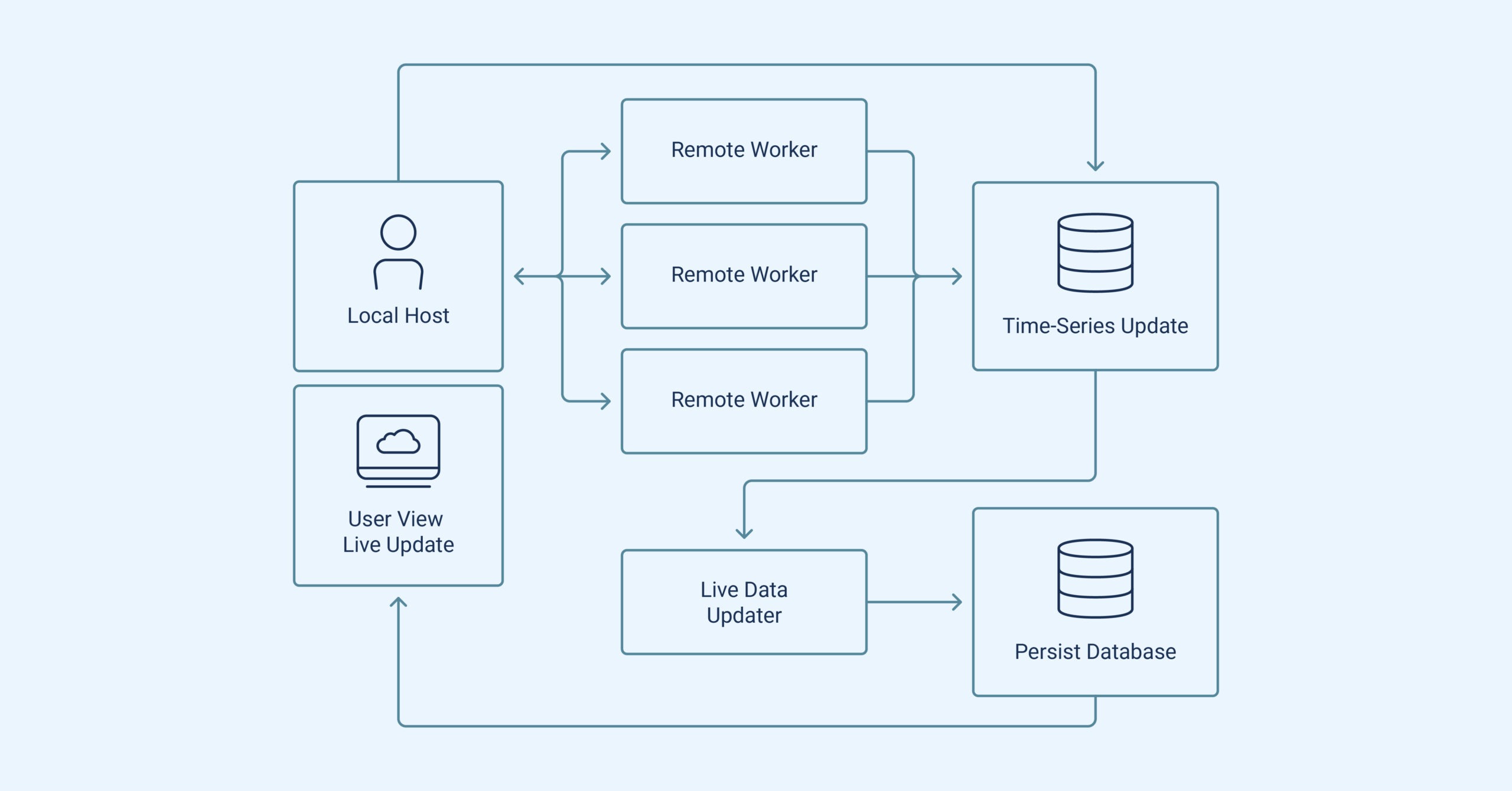
Consequently, vital questions about ongoing job progress, like performance bottlenecks, have been un-addressable. The framework also gathers data locally during execution, which is subsequently transmitted to the user, hindering real-time troubleshooting. I was challenged to design an end-to-end system that would interact with Research factory to achieve the goal of accessing approximately-live data across millions of daily jobs.
Approach
The solution needed to accommodate varying compute locations and allow users to capture customized real-time metadata about job progress. My approach involved locally batching updates and flushing them to a time-series database through a separate process for persistence. Recording only differences also minimized overhead when translating data from streams to a persistent format via an out-of-band process. This design enabled easy querying of real-time job status using provided APIs.
Results
After implementing the deploy pipeline, the system was ready for migration to production. This project highlighted the importance of understanding infrastructure challenges. It reinforced the idea that infrastructure serves as a foundational tool for other teams and that the reliability of this system has a direct impact on their work.

Generalized framework for generating back populated datasets
Nicholas Grill, Carnegie Mellon University
Challenge
Data back population is crucial for Pricing Research and commonly includes three steps: formulating pricing algorithms, applying them to historical data and analyzing derived metrics.
Standardizing these steps enhances research efficiency, streamlining the iteration loop. While diverse solutions tailored to specific projects have emerged within the firm, they often duplicate problem-solving efforts related to data organization, versioning, regression testing and scalability. A unified approach would address these recurring challenges and optimize the research process.
Approach
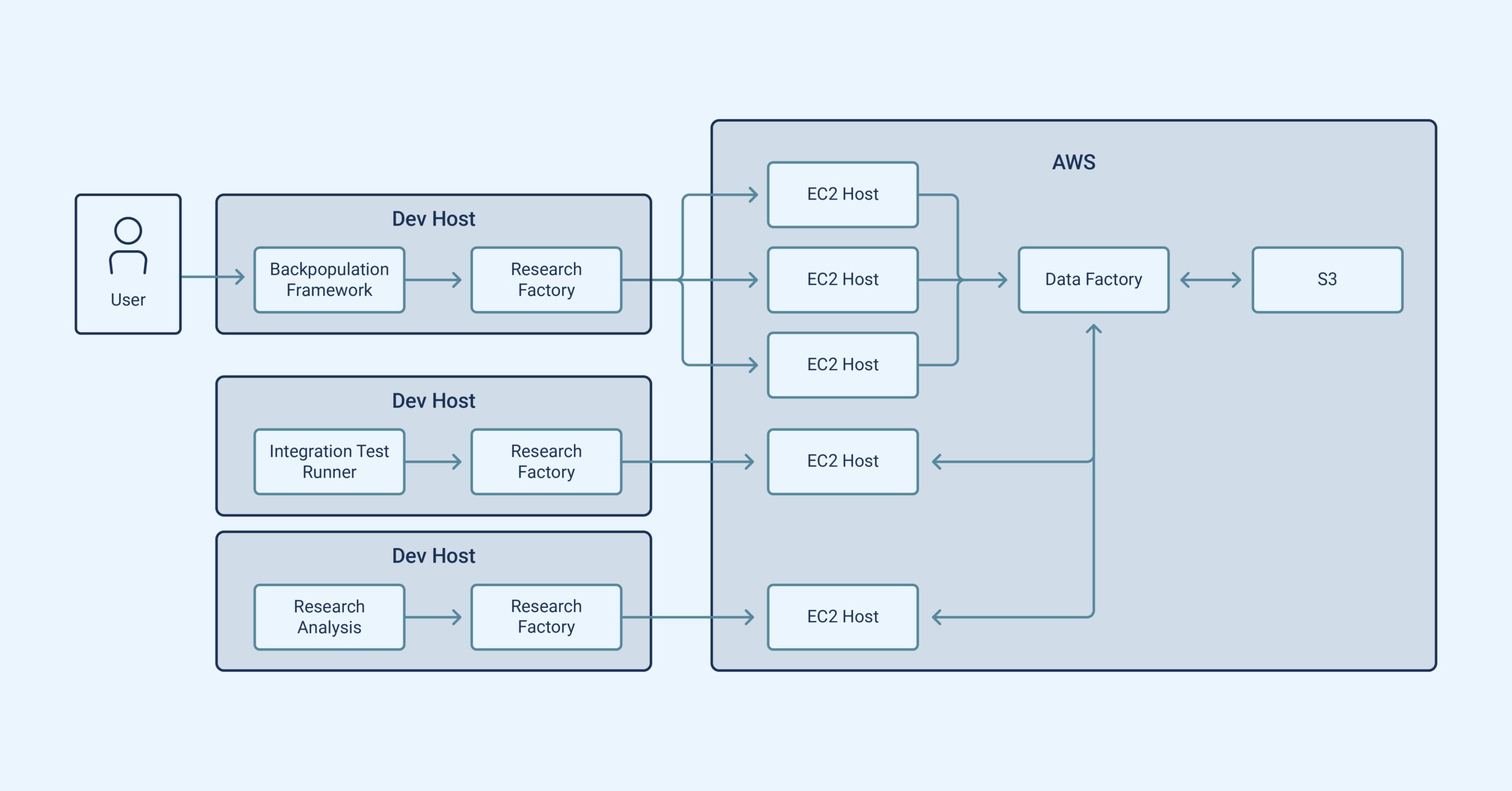
This summer, I devised a versatile Python framework for back populating historical datasets. The framework caters to developers, researchers, and traders by offering customizable entry points for business logic while abstracting essential infrastructural aspects like S3 data storage, argument parsing, versioning and normalization.
Utilizing familiar tools like Numpy and Pandas, researchers create data frames, which the framework wraps and persists. Metadata-tagged back-populated data ensures orderly storage and enables standardized retrieval. The framework even facilitates SQL-like queries for data access, smoothly integrating with existing Postgres datasets.
Results
My framework offers more than a research utility, extending to regression testing and allowing users to define data generation and reference data comparison. This combination enables potent regression tests where new code-generated data is compared to established reference data, ensuring robust code changes. This practice enhances production environment safety and accelerates development by diminishing the need for manual system tests.
Scaling up to numerous symbols and years is also seamless as Optiver’s internal Research Factory tool integrates with the framework to schedule work across AWS EC2 nodes, relieving researchers of infrastructure concerns. My framework has already aided the migration of three datasets and will support more soon.





